
Students at high level institutions are violating academic integrity; however, a deeper analysis showcases that this is a beneficial strategy for most of them.
Students at high level institutions are violating academic integrity; however, a deeper analysis showcases that this is a beneficial strategy for most of them.
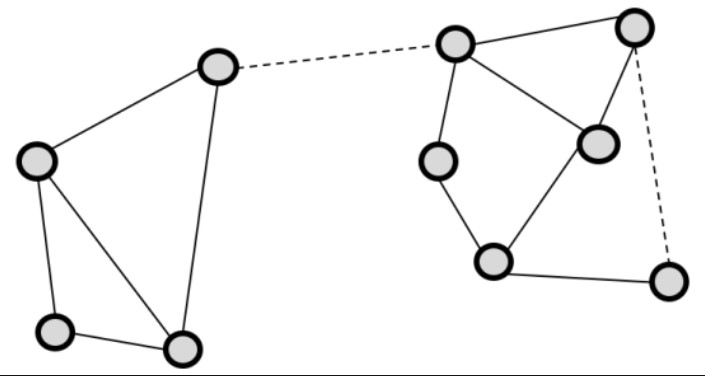
When it comes to the concept of connections, the weaker it is, the more valuable it becomes. We explore this oxymoron in this post and its relationship to graph theory.
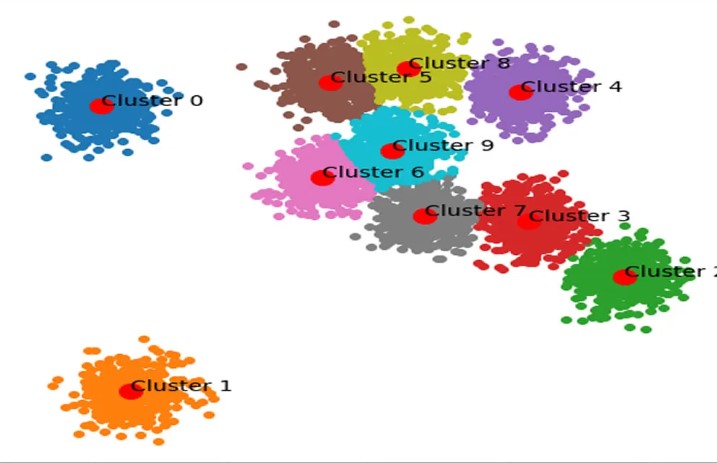
The NMI and ARI are metrics we observe all the time in clustering analysis. But, what exactly makes them different? When do we use one versus the other? When do they attain optimal values? All shall be explored here!
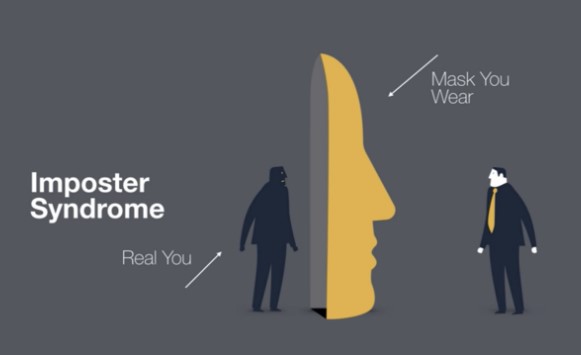
In this post, at the risk of being too open and vulnerable, I share how I have struggled with impostor syndrome, what it truly feels like, and ways I have found to break through it that I hope might help others.

With the help of Monte Carlo simuilation and multiprocessing, we use Python to simulate poker hands and make an inference on bad beat jackpots... which live poker players won't stop talking about... ever.
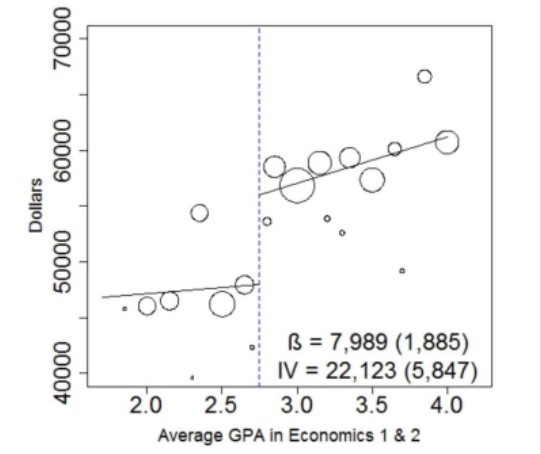
Regression discontinuity design is used to estimate a treatment effect. However, people are getting carried away with the conclusions of such an analysis. (NOTE: Cite Deb's work)
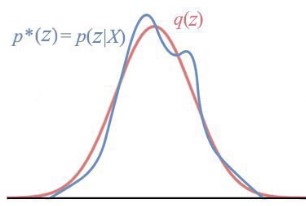
Variaional inference is a very hot topic right now. However, without a concrete example, it can be difficult to understand the motivation behind such a technique. We motivate it here with a very simple example.
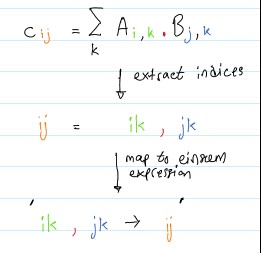
Einstein summation is an incredibly useful tool for implementing products along common axes for multiple matrices. Its application in dimensionality techniques is beautiful and merits at least a glance, if not a full understanding of its use in CP-ALS implementation.

The Netflix Prize was an open data science compeition that attempted to find the best filtering algorithm to predict ratings for films. However, despite some eye-opening results, this content had one major flaw.
LightGBM is one of the most innovative decision tree implementations on the market right now. Let's explore what it does on Zero-Inflated data and why it happens.
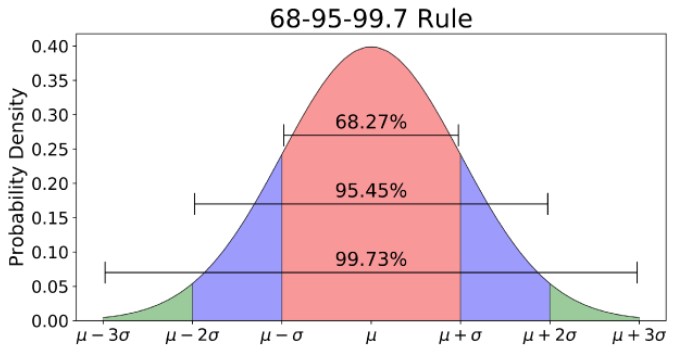
If you're familiar with the normal distribution and R programming, then it's likely you've learned to use pnorm to calculate p-values for analysis. However, the way a computer does this calculation is lesser known. Let's change that!

If you've ever played a game at a casino that has a roughly 50% chance of winning, then you may have heard about the martingale betting system. However, if you're aware of the strat, so is the house. Here we visually understand how casinos have disrupted the implementation of this strategy. (EV GRAPH)
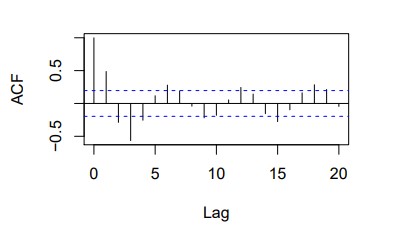
After learning that the AR(2) ACF is sinusoidal, I wanted to actually prove it. We showcase some examples of this being the case and then detailing the algebraic mess that proves it.
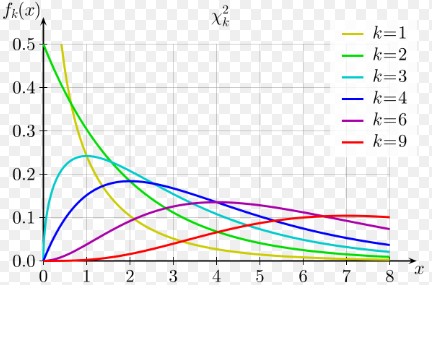
The chi-square distribution (and tests of independece/goodness of fit) are characterized by their degrees of freedom. However, many times we just memorize the formulas for it and don't understand where it stems from. Here, we provide some perspective on the origin of these formulas.
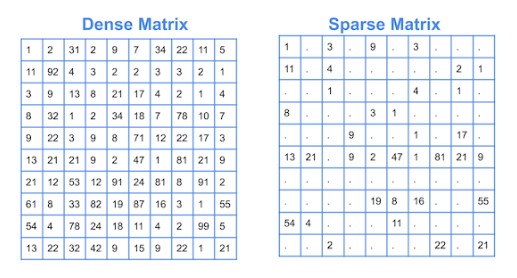
Sparse data is common in statistical analysis; there are always going to be applications that have zero-inflated observations and finding the right tools to deal with it is important. Scipy sparse is a package that helps with this setting, but a more concrete exploration of when its better than more traditional approaches is warranted.
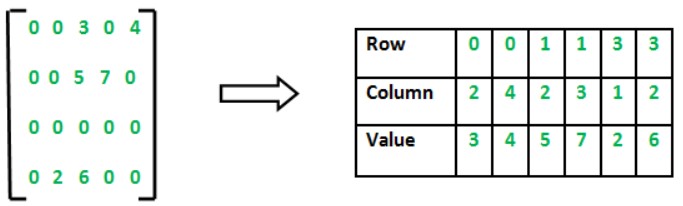
CSR is a technique that is used to perform matrix operations in sparse settings. However, even if you understand the big picture, it can be overwhelming to understand how it works. In this post, we explain how CSR works and provide a myriad of cases to flush out the CSR mechanism.